

神経科学の発達によって、ヒトやサルなどの霊長類の脳のどこの部位がどんな機能を持っているのか、その地図が明らかになってきた。これを脳地図というが、その中でもとくに視覚系の研究が進んでおり、詳細な地図を描くことができるようになった。外界の物や風景は、眼の網膜を通って大脳の中の最後部にある一次視覚野にまず伝えられる。次いで、その情報は一次視覚野の前方に広がる視覚連合野と呼ばれる領域に伝えられ、そこで色や形、動きなどの情報処理が行われる。こうした脳の活動を明らかにする上で大きな役割を果たしてきたのが、脳波計や脳の血流の変化などを計測できるfMRIである。
神谷室長が所属するATRでは、これまでにも脳の知覚情報を解読する研究を継続的に行ってきた。2006年には、ホンダ・リサーチ・インスティテュートとの共同研究で、じゃんけんをするときの脳の運動野の血流量の変化をfMRIを使って読み取り、その解析データをロボットハンドに送り、ほぼリアルタイムで被験者と同じ動作をさせるという実験で注目された。
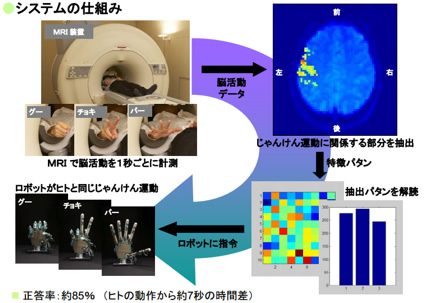
この研究は「ロボットがジャンケンをする」というので、その面白さで話題になったが、実は、脳神経科学の領域において注目すべきものであったという。
「これまでの神経科学の研究では、被験者に外界から刺激(課題)を与えたときに生じる脳活動を観察し、脳が外界からの情報をどう受け取っているかを明らかにしてきました。しかし、人間の意識を解読するためには、これとは逆に、脳で起きている活動からどんな刺激や課題が与えられたのかを推定しなければなりません。これを「デコーディング」といいます。じゃんけんをするロボットの場合には、じゃんけん動作を行っているときの脳活動から、グー・チョキ・パーの動作を判別する数理的なモデル(デコーダ)をつくり、ロボットに指令を出したわけです。
ただ、この方法の場合、あらかじめグー・チョキ・パーそれぞれの場合の刺激を計測・学習しており、選択肢も3通りと少なく、どんな脳活動でも解読できるというわけではありませんでした」
そこで、神谷室長たちは、学習済みのカテゴリーに分類して予測するのではなく、被験者が見ている画像をそのまま復元することに挑戦することにした。
しかし、画像の復元は容易ではない。画像はピクセル(画素・ドット)が集まり、組み合わさって構成される高次元のデータで、情報量が膨大だから、脳の中にある画像を一括処理して解読しようとするのは不可能だ。たとえば10×10ピクセルのサイズの白黒画像を予測することを考えても可能な選択肢は10の30乗にものぼる。
そこで神谷室長らが採用したのが「モヂュラー・デコーディング」と呼ばれる手法だ。画像全体を小規模な部分データへと分解し、小領域ごとに予測(解読)を行い、それらを組み合わせることで画像を再構成するのである。分かりやすくたとえると、漢字は膨大な数があるけれど、偏と旁に分けて組み合わせれば処理しやすくなるのと同じ発想法だという。
「被験者には白と黒の440個の画像を見せ、視覚野の血流の変化をfMRIで計測し、脳の活動パターンをコンピュータに覚えさせてデータ化しました。このデータを元にして、実際に見ている脳内の画像を取り出してコンピュータで再現するプログラムを開発したのです。その結果、1億通り以上の画像種を再構成することができました」
被験者に四角形や十字、アルファベットなどの11種類の画像を見せた4秒後には、見ている画像をコンピュータで再現することができたのだ!
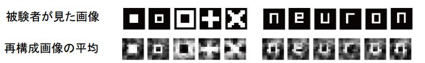
▲ 幾何学図形やアルファベットの形の再現に成功

こうして視覚画像を再現することに成功した後、神谷室長たちは、夢の解読に挑戦していった。
「画像を頭の中で想像しているときにも、実際に画像を見ているときと同じように視覚野が働いているという報告があり、私たちは実際の画像の再現方法を使って、夢の内容を再現することができると考えたのです」